Over the past decade, robotic neurorehabilitation has become one of the most discussed innovations in neurological recovery. Robotic gait trainers, upper-limb rehabilitation systems, exoskeletons, and AI-assisted rehabilitation devices are increasingly being adopted by hospitals and rehabilitation centres worldwide. However, an important question remains: Are robots the future of neurorehabilitation—or are they simply another tool in the rehabilitation toolbox? As clinicians and researchers, we must move beyond marketing claims and focus on scientific evidence, patient selection, and clinical reasoning. What is Robotic Neurorehabilitation? Robotic neurorehabilitation involves the use of electromechanical devices that assist, guide, resist, or augment movement during therapy. These technologies include: • Robotic gait trainers • Wearable exoskeletons • Upper limb robotic rehabilitation devices • End-effector robotic systems • Sensor-based rehabilitation platforms • AI-assiste...

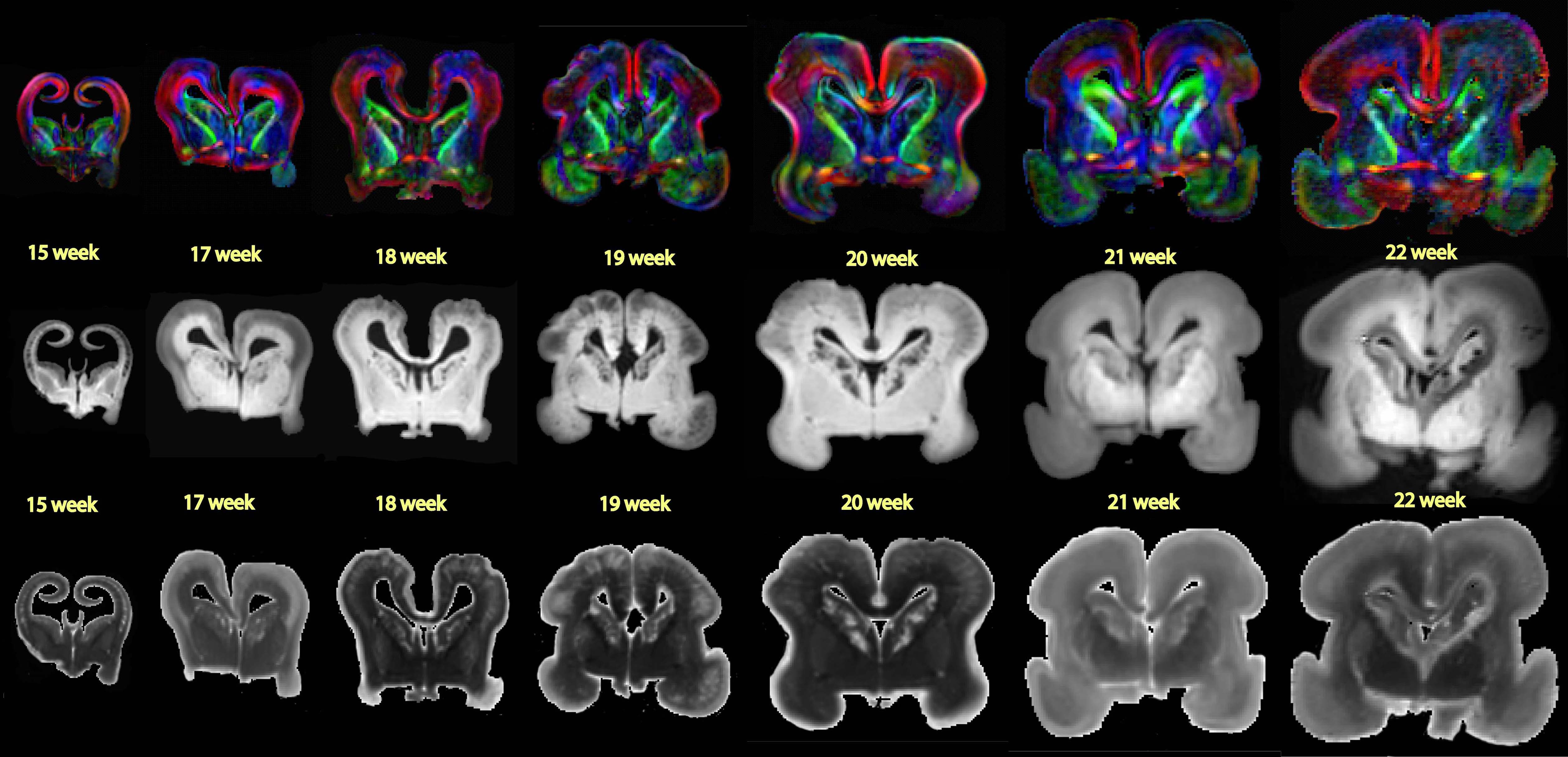
The analytical model used to estimate
critical conditions at the onset of folding in the brain is based on the
Föppl–von Kármán theory. This theory is applied to approximate cortical folding
as the instability problem of a confined, layered medium subjected to
growth-induced compression. The model focuses on predicting the critical time,
pressure, and wavelength at the onset of folding in the brain's surface
morphology.
The analytical model adopts the classical fourth-order plate equation to
model the cortical deflection. This equation considers parameters such as
cortical thickness, stiffness, growth, and external loading to analyze the
behavior of the brain tissue during the folding process. By utilizing the
Föppl–von Kármán theory and the plate equation, researchers can derive
analytical estimates for the critical conditions that lead to the initiation of
folding in the brain.
Analytical modeling provides a quick initial insight into the critical
conditions at the onset of folding, allowing researchers to understand the
fundamental mechanisms driving cortical folding. However, it may not fully
capture the evolution of complex instability patterns in the post-critical
regime. Therefore, while the analytical model helps in estimating the critical
parameters for folding initiation, a computational model based on the continuum
theory of finite growth is often employed to predict more realistic surface
morphologies and complex folding patterns beyond the onset of folding.
In conclusion, the analytical model based on the Föppl–von Kármán theory
provides a foundational framework for understanding the critical conditions
that trigger folding in the brain's surface morphology. It serves as a valuable
tool for estimating key parameters at the onset of cortical folding and guiding
further computational modeling efforts to explore the evolution of brain
surface morphologies.
Comments
Post a Comment